
AI说话的时代,终于不用等它把整句话读完了。
就在几天前,李沐联合创立的Boson AI发布Higgs Audio v3 TTS,直接接入SGLang推理框架。这个模型最狠的地方:不用等完整句子出现,拿到几个字就能开始合成语音,而且前后音色、情绪、语速完全一致。
一、111种语言,个位数错误率
传统TTS做多语言,翻车是常态。
Higgs Audio v3覆盖111种语言和方言,100种语言上的语音识别错误率全部达到个位数。更狠的是零样本声音克隆——给一段短参考音频,就能复现目标音色,还能跨语言迁移。
也就是说,你说中文的声音,可以直接用来合成英文、日文、法文。
二、情绪、风格、音效,全靠文本控制
开发者直接在文本里写控制标记就行。
20多种情绪随意切换,说话风格、语速、音高、停顿,甚至环境音效,全部在一段文本流里搞定。不用分开调用不同接口,一个模型全包。
三、为什么需要SGLang-Omni?
传统推理框架只管一个解码循环。但Higgs这类新模型有多个计算阶段——有的像自回归解码,有的像轻量级计算,有的要实时接收文本输出音频。
SGLang-Omni从系统层面对多阶段流程统一调度,每个阶段按自己的计算特性运行,显存隔离、通信解耦、进程拓扑统一管理。
单张H100上,生成速度已经超过音频播放速度。
四、这意味着什么?
语音智能体、数字人、多语言AI Agent,这些场景的核心瓶颈一直是延迟和自然度。Higgs Audio v3把这两个问题同时解决了。
加上SGLang的开源推理生态,开发者现在就能用几行代码把语音能力接进自己的系统。
当AI不仅能听懂你,还能用你的声音实时回应你,人机交互的边界又往前推了一大步。
你觉得,语音AI最先颠覆的会是哪个行业?
 Oracle XStream CDC实测:37000 TPS下性能影响全面评估!
Oracle XStream CDC实测:37000 TPS下性能影响全面评估!
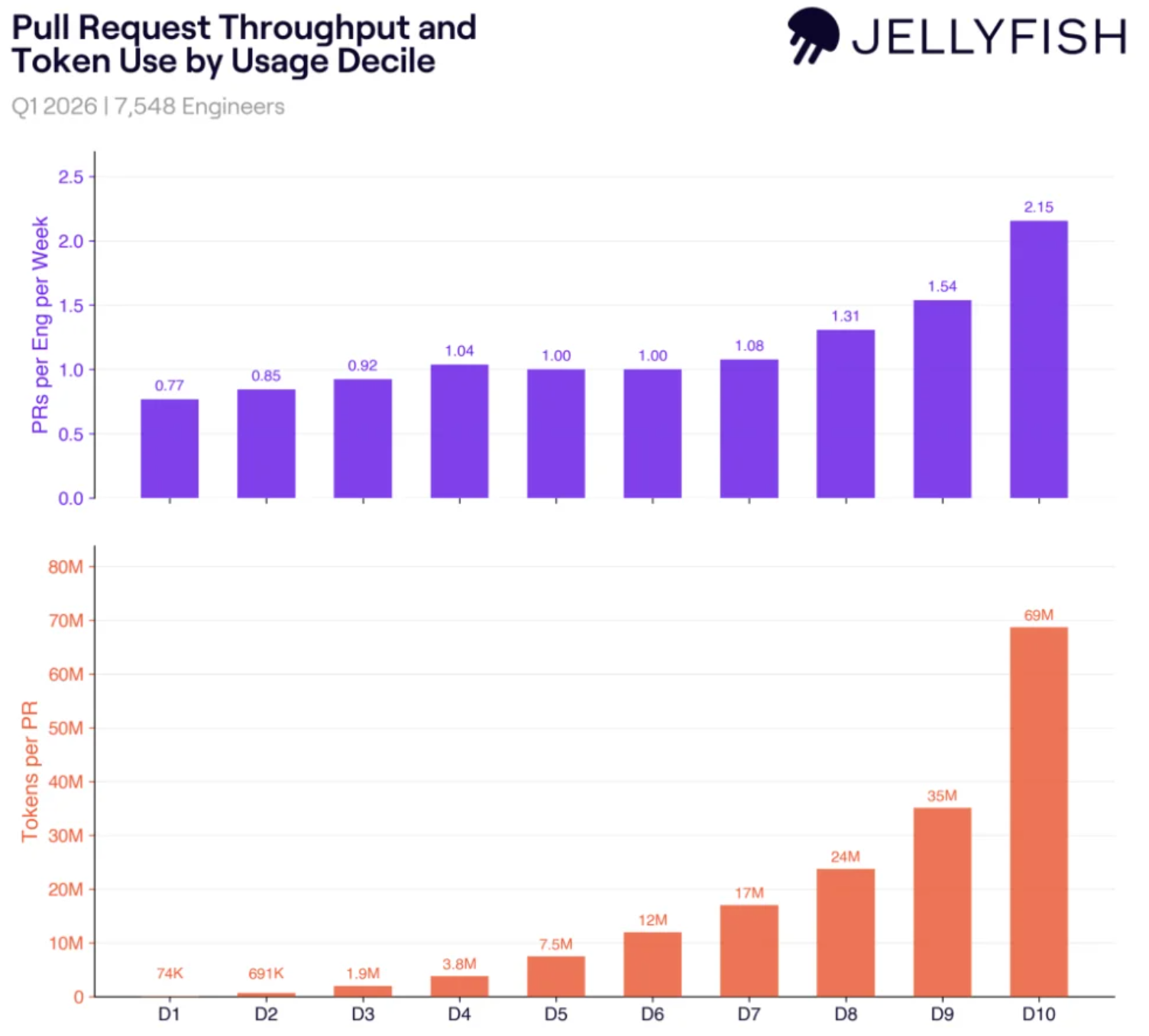 30天烧60万亿token,扎克伯格没进前250:大厂AI沦为KPI游戏!
30天烧60万亿token,扎克伯格没进前250:大厂AI沦为KPI游戏!
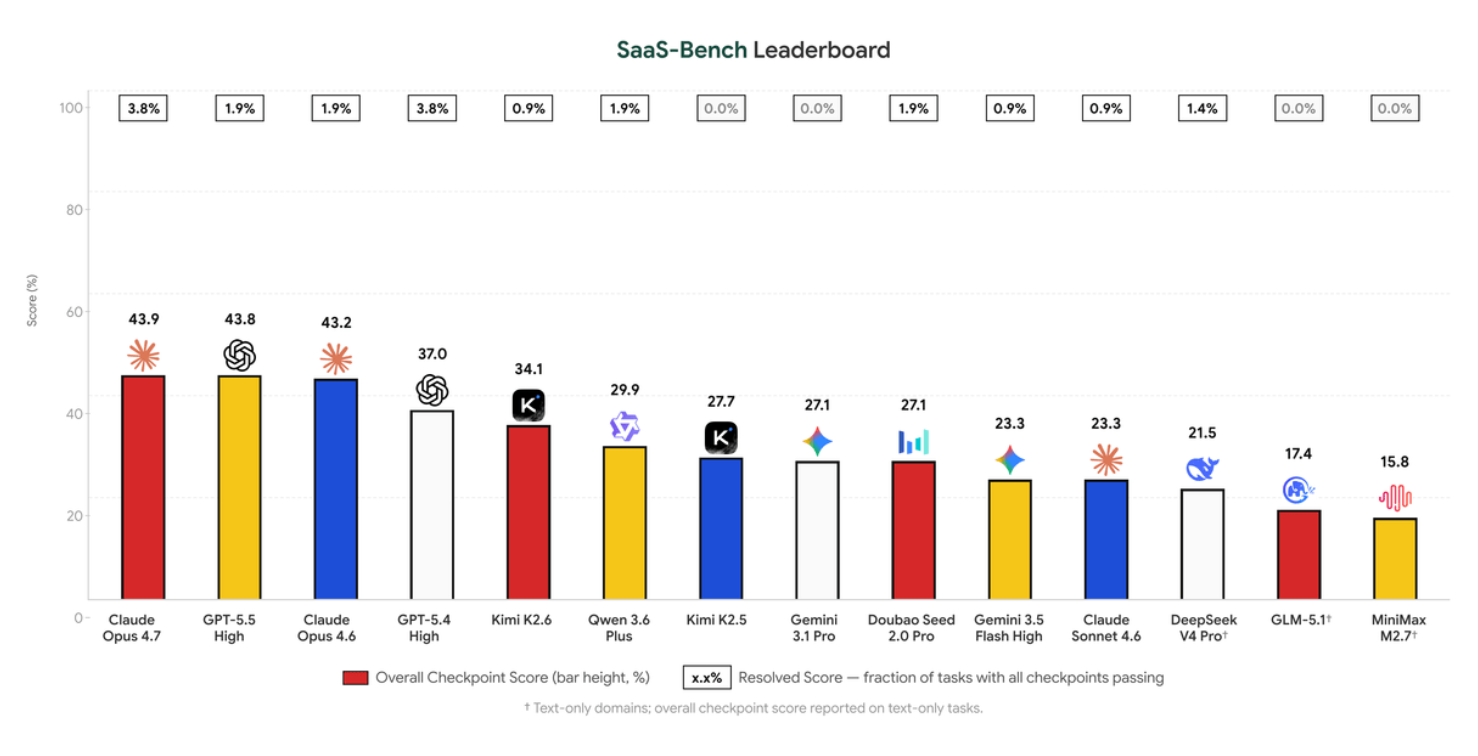 SaaS-Bench实测23个真系统:最强AI Agent仅完整通过4个任务!
SaaS-Bench实测23个真系统:最强AI Agent仅完整通过4个任务!
 Waymo无人车再陷积水困境,特斯拉FSD却越开越像老司机!
Waymo无人车再陷积水困境,特斯拉FSD却越开越像老司机!
 面壁智能三值量化突破:6倍省显存,600亿参数模型装进手机!
面壁智能三值量化突破:6倍省显存,600亿参数模型装进手机!
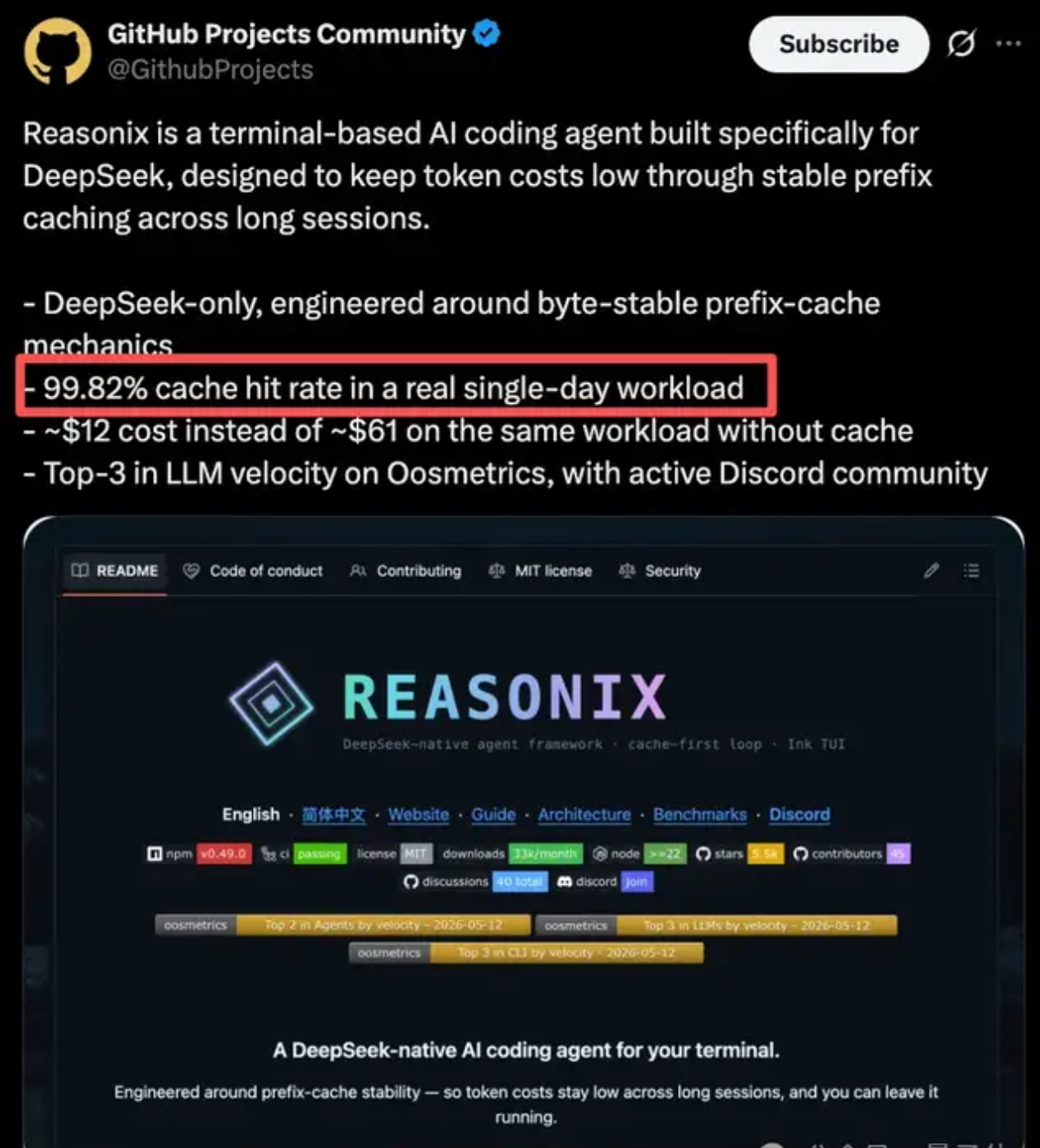 DeepSeek省钱神器Reasonix:缓存命中99.82%,4亿token账单直降80%!
DeepSeek省钱神器Reasonix:缓存命中99.82%,4亿token账单直降80%!
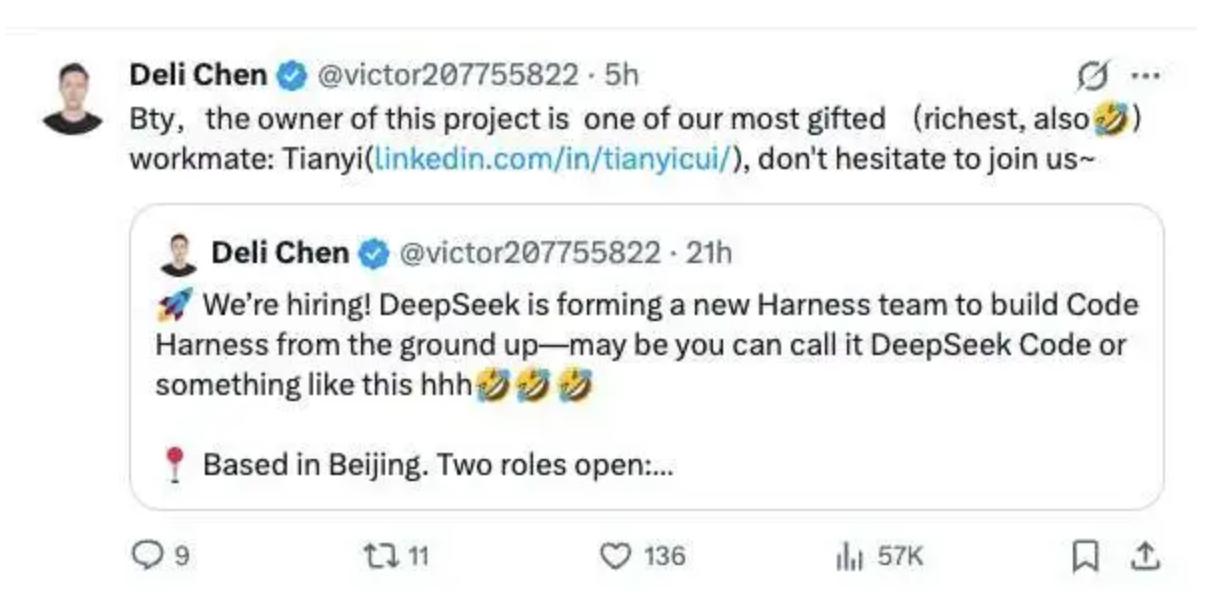 DeepSeek对标Claude Code组建Harness团队:模型之外,控制层决胜!
DeepSeek对标Claude Code组建Harness团队:模型之外,控制层决胜!
 GPT-5.5被实锤"降智":200美元买的旗舰模型,背后偷偷换成了mini!
GPT-5.5被实锤"降智":200美元买的旗舰模型,背后偷偷换成了mini!
 华为大模型负责人创业:一个框架帮Agent省75%的token钱
华为大模型负责人创业:一个框架帮Agent省75%的token钱
 微软叫停内部Claude Code:一场"用不起"背后的三重困境!
微软叫停内部Claude Code:一场"用不起"背后的三重困境!